Overview
In the rapidly evolving world of web3 and the open metaverse, decentralization stands as a fundamental principle. The concept of an "open metaverse" is built on public data, collectively verified by many participants, resulting in immutability and transparency. This architecture enables the transfer of value via cryptocurrencies and the ownership of digital assets through NFTs. However, with these innovations comes a critical challenge: how do we store data in alignment with decentralization principles?
The Storage Dilemma in Decentralised Systems
When building daecentralised applications, developers face a fundamental question: where and how should data be stored? Let's explore the current landscape of options and their limitations:
Blockchain Storage: Limited by Design
Storing data directly on the blockchain seems like the most daecentralised approach. However, this method quickly becomes impractical due to extremely limited storage capacity and prohibitively high costs for even small amounts of data. Additionally, blockchain networks suffer from congestion and scalability issues when storing significant amounts of information. The performance limitations for retrieving large datasets further compound these problems, making on-chain storage viable only for the smallest pieces of critical data.
Decentralised Storage Protocols: The IPFS Challenge
Protocols like InterPlanetary File System (IPFS) are often used by developers to mitigate the storage limitations associated with blockchains. While IPFS offers significant advantages, it introduces its own set of challenges, at least for certain use-cases.
Performance and latency issues plague IPFS as retrieval times can be unpredictable since content needs to be found on the peer network. Initial content access can be frustratingly slow if content isn't well-pinned or distributed, and geographic distribution of nodes can lead to variable performance across different regions.
Data persistence represents another significant concern with IPFS. Content needs to be actively pinned or it may become unavailable over time. Users must run and maintain IPFS nodes or rely on third-party pinning services, adding complexity and cost. There are no guarantees that data will remain available without continued maintenance, creating uncertainty about long-term storage reliability.
Access control limitations further complicate IPFS adoption. Transparency is inherent to decentralization, making the implementation of data permission controls complex. Resorting to encryption solutions introduces key management challenges that many developers and users struggle to implement correctly. The system also lacks native support for granular permissions or role-based access, limiting its applicability for applications that require more sophisticated data access patterns.
Authenticity verification represents another crucial limitation. IPFS lacks native mechanisms to prove that a file was authored by a particular identity. Without this capability, users have no cryptographic guarantee that the content they're accessing was actually created or published by the claimed author, creating potential for impersonation and content manipulation while undermining trust in the system.
Data Sylos: A Pragmatic Approach to Decentralised Storage
The fundamental issue isn't that we lack storage solutions - it's that we need interoperability and choice. Data Sylos represent a practical step toward solving the storage layer challenge for the open metaverse.
What are Data Sylos?
Data Sylos are independent nodes that provide data services for the open metaverse, built on Sylo protocols and powered by the $SYLO token. They deliver three critical features:
- Verifiability: Authenticity and integrity of data can be cryptographically proven
- Access Control: Permissions can be managed without sacrificing decentralization principles
- Flexibility: Data can be stored using various underlying storage solutions, identified by Daecentralised Identifiers (DIDs)
This approach acknowledges that different applications have different storage requirements. Instead of forcing a one-size-fits-all solution, Data Sylos allow applications and users to choose their preferred storage mechanism while maintaining interoperability.
Bringing Choice to Data Storage
Imagine being able to "plug in" a storage service of your choice into apps you use, where your data is stored on infrastructure you control or by a provider you trust. This is the vision of Data Sylos - creating a world where users can control where their data is stored, developers can integrate with multiple storage providers through a unified protocol, and data can move freely between applications without being locked to specific platforms.
The Sylo Data Verification Protocol
At the heart of Data Sylos is the Sylo Data Verification Protocol. This protocol addresses two fundamental challenges in decentralised storage:
1. Reliable Data Resolution
A common problem with decentralised storage networks is that they rely on peer-to-peer protocols to replicate data across the network. While a file may exist somewhere within the network, there's no guarantee that a client will be able to reliably locate the provider of that file.
The Sylo Data Verification protocol solves this by recording the resolution method on-chain, making it significantly more reliable for any client to discover how to fetch that data.
2. Data Authenticity Without Trust
In traditional systems, data passes through multiple intermediaries before reaching the end user. This creates multiple points where data could potentially be tampered with, forcing users to trust each intermediary in the chain.
The Sylo Data Verification protocol eliminates this need for trust by providing cryptographic verification of data authenticity. Even when data is served by a middle-man, users can verify that they've received exactly what the original creator intended.
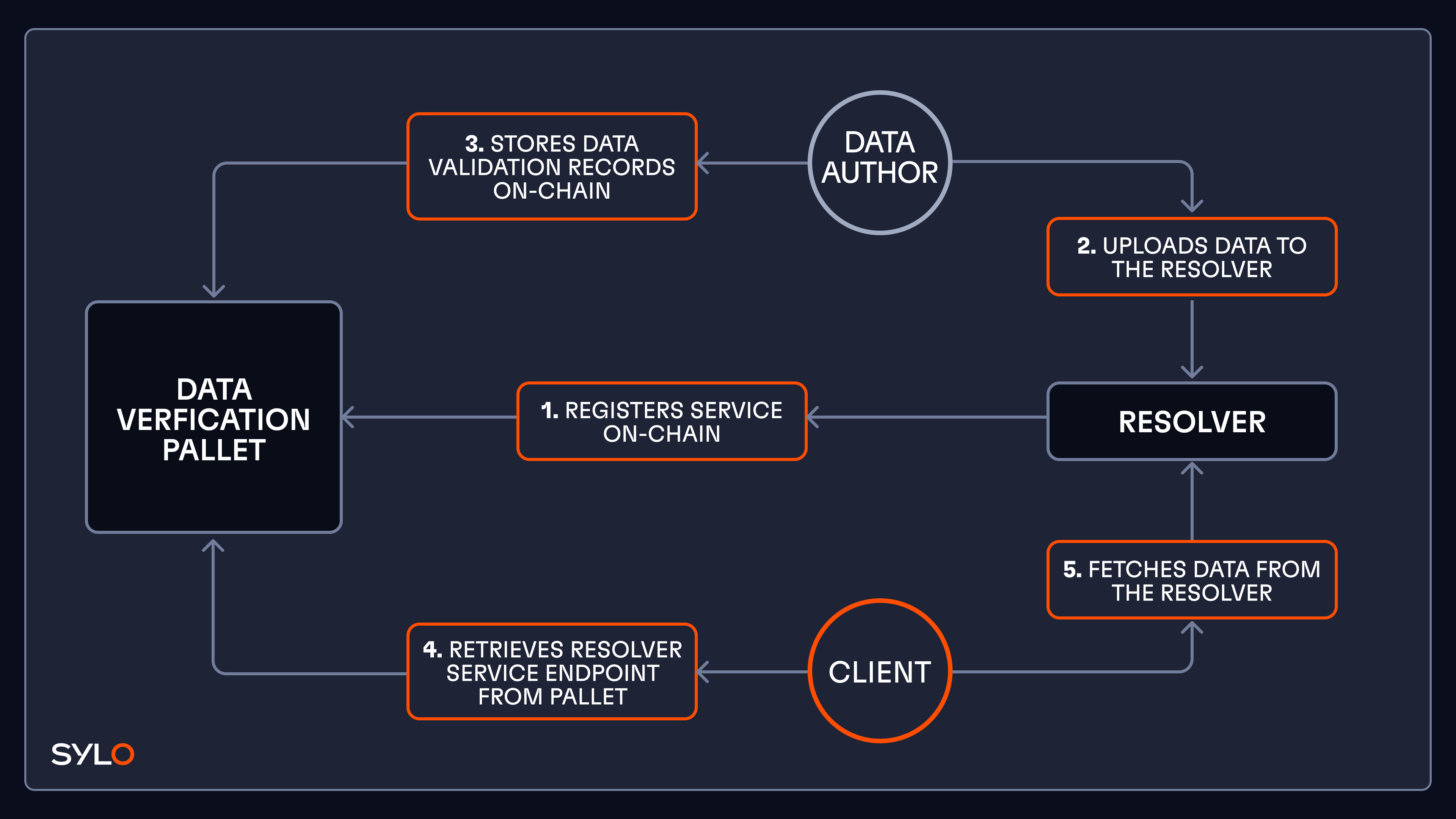
Technical Implementation: The Sylo Data Verification Pallet
This pallet is deployed on The Root Network (TRN), and is responsible for storing validation records and also acting as a registry for resolvers.
Data Sylo used as a data resolver for the open metaverse
A Data Sylo is a service that can be used to upload and fetch the data associated with a validation record. A DID is issued when a data owner uploads data, which can be used by others to download the data.
The backend implementation of a Data Sylo is not strictly enforced by the protocol - we look forward to how the protocol gets used by developers. The first implementation of a Sylo at Futureverse will use an S3 backend, and serve files via HTTP GET requests. This containerised implementation is planned to be open-sourced, so anyone can start running their own Data Sylo node.
Registering a Sylo
To enable data on Sylos to be discoverable, the Data Verification Pallet acts as a registry where Sylos can be registered as resolvers. Every piece of data that is registered with a validation record can be discoverable with this linkage to a registered Sylo.
// Register a new resolver.
///
/// The caller will be set as the controller of the resolver.
pub fn register_resolver(
origin: OriginFor<T>,
identifier: BoundedVec<u8, T::StringLimit>,
service_endpoints: BoundedVec<ServiceEndpoint<T::StringLimit>, T::MaxServiceEndpoints>,
)The extrinsic register_resolver is used to register a Sylo on-chain. The caller will be set as the “controller” of the Sylo, which is the TRN account that owns and operates the Sylo. The extrinsic requires passing in a set of service endpoints. A service endpoint is where the Sylo’s API is hosted, and it is how data is uploaded and fetched from the Sylo.
Recording a validation record
A validation record is a structure that is persisted on-chain, and allows a third-party to verify the integrity and authenticity of data. Data integrity is achieved through a SHA256 checksum, and authenticity is achieved by enforcing that records can only be created or updated by the Data author (represented by a TRN account ID).
Validation records will be created and updated via extrinsics sent to the pallet. The validation record is indexed by the data author’s account ID, and also a data ID string value. The data ID is set by the author when first creating the validation record. The combination of account id + data id must be globally unique.
/// Create a new validation record.
///
/// The caller will be set as the record's author.
///
/// For any specified resolvers which use the reserved sylo resolver
/// method, those resolvers must already be registered and exist in storage.
///
/// The initial record entry will use the current system block for the
/// block value.
pub fn create_validation_record(
origin: OriginFor<T>,
data_id: BoundedVec<u8, T::StringLimit>,
resolvers: BoundedVec<ResolverId<T::StringLimit>, T::MaxResolvers>,
data_type: BoundedVec<u8, T::StringLimit>,
tags: BoundedVec<BoundedVec<u8, T::StringLimit>, T::MaxTags>,
checksum: H256,
)Sylos and verification protocol in practice
We have worked with our team at ALTERED STATE to productionize this technology. ALTERED STATE is a generative tool that transforms users thoughts and creativity into game-ready 3D models using AI. ALTERED STATE assets can be published on The Root Network as an NFT.
ALTERED STATE uses the Universal Blueprint Framework (UBF) ensuring they are fully interoperable assets that are game-engine agnostic, meaning they work across Unity and Unreal Engine. Published ALTERED STATE creations can be playable today in The Readyverse.
UBF assets contain a number of related data files. These files are registered on-chain through Sylo Protocols and stored against the ALTERED STATE Data Sylos.
Let’s dig in a little deeper.
Validation Record
We have the following mesh file for ALTERED STATE:
{
"id": "as-mesh-27342",
"uri": "did:sylo-data:0xffFfFFfF000000000000000000000000000C5CD4/3a5e75e0-7b0b-4eaa-9796-2e015c6af73b?resolver=fv-altered-state-sylo",
"hash": "0x9e23fe24d0917c4da531a5a313dcfe891520bb9679b5ca43342be4dfb745a478"
}The DID is structured as follows:
did:sylo-data: the DID method is identified as sylo-data0xffFfFFfF000000000000000000000000000C5CD4: the data owner for ALTERED STATE - the EOA for this Pass address can be matched against the collection owner of the ALTERED STATE NFT Collection, ensuring authenticity of source3a5e75e0-7b0b-4eaa-9796-2e015c6af73b: the data-id, a unique identifier that matches this file?resolver=fv-altered-state-sylo: optional query parameter that embeds the resolver-id for where the data is stored
We can query the blockchain using the did to get the following response:
{
author: 0xffFfFFfF000000000000000000000000000C5CD4
resolvers: [
{
method: sylo-data
identifier: fv-altered-state-sylo
}
]
dataType: OBJECT
tags: []
entries_: [
{
checksum: 0x9e23fe24d0917c4da531a5a313dcfe891520bb9679b5ca43342be4dfb745a478
block: 22,956,212
}
]
}Querying for the verification record using the DID, we are able to:
- Validate that the author of the data is
0xffFfFFfF000000000000000000000000000C5CD4which provides authenticity. Only the owner of the wallet, that matches the address of the ALTERED STATE collection owner could have created this record. - Discover which Data Sylo should be queried to fetch this data. This matches the query parameter for
resolver. The actual endpoint can also be queried usingsyloDataVerification.resolvers. - Verify the data was in its original state using the checksum, and compare it against an independently generated checksum of the file downloaded.
So what does this mean? We know that only the Altered State Collection Owner is capable of authoring the verification record and the checksum stated in the verification record matches our own independently generated checksum. We can be confident that our mesh file is valid and authentic.
This validation process allows us to store large amounts of data using traditional storage infrastructure, without comprising on the decentralised benefits that blockchains provide us.
The whole process of resolving data that is associated with DIDs stored in Data Sylos, is easy using Futureverse SDKs.
What’s next for Sylo
The Sylo Data Verification pallet is live on The Root Network and you can check out the docs. In the next article, we’ll explore the next Sylo Protocol - Data Permissions. This extends the utility of Sylos for Data Owners to maintain control over permissions around their data that they’ve made available in the open metaverse.
Futureverse will continue to deploy a number of Data Sylos that power Futureverse projects, such as hosting UBF files and blueprints used for rendering Futureverse Collectibles and other data-layer items that power the open metaverse. There will also be other types of Sylos, such as JSON Storage Sylos, deployed, optimised and feature rich for storing structured data.
Bringing it all together
The Sylo Data Verification Protocol represents a pragmatic solution to one of the most challenging aspects of building a truly open metaverse - reliable, verifiable data storage that doesn't sacrifice decentralisation principles. By focusing on verification, reliable resolution, and choice rather than enforcing a specific storage technology, Sylo Protocols enable a more flexible and interoperable ecosystem.
As we continue to build the infrastructure of the open metaverse, solutions like the Sylo Data Verification Protocol provide the essential building blocks that will allow developers to create experiences where users truly control their data and digital assets.
Read the Sylo Network Update Paper and to stay up-to-date with developments and join our growing community, follow us on X and join our Discord.
